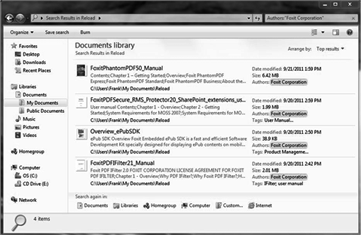
Foxit PDF IFilter adalah implementasi yang kuat dari antarmuka pengindeksan Microsoft IFilter. Ia bekerja dengan semua pencarian dan pengambilan produk yang mendukung antarmuka IFilter (misalnya, SharePoint dan SQL Server). Produk tersebut menggunakan program format khusus Filter (disebut iFilters) untuk format file tertentu (misalnya, HTML). Foxit PDF IFilter adalah program seperti itu, ditujukan untuk dokumen PDF. User interface untuk mencari dokumen mungkin Windows Explorer, browser web, frontend basis data, naskah permintaan, atau aplikasi kustom. Foxit PDF IFilter bertindak sebagai plug-in untuk mesin pencarian teks lengkap. Sebuah mesin pencari biasanya bekerja dalam dua langkah: * Mesin pencari melewati tempat yang telah ditentukan (folder file atau database), indeks semua dokumen atau dokumen yang baru dimodifikasi (termasuk dokumen PDF), dan kemudian toko mengindeks hasil dalam database internal. * Pengguna menentukan kata kunci yang ingin mencari, mesin pencari mendongak hasil pengindeksan dalam database internal, dan kemudian menanggapi pengguna dengan semua dokumen yang mengandung kata kunci tertentu. Selama langkah 1, mesin pencari itu sendiri tidak memahami format dokumen PDF. Oleh karena itu, terlihat di registri Windows untuk PDF IFilter yang tepat dan menemukan Foxit PDF IFilter. Karena PDF IFilter memahami format PDF, itu menyaring format tertanam, ekstrak teks dari dokumen, dan kemudian kembali teks kembali ke mesin pencari. Fungsi Foxit PDF IFilter di lingkungan mesin pencari berikut: * Microsoft SharePoint Server: SharePoint Server 2007, SharePoint Server 2010, SharePoint Server 2013 * Microsoft Exchange Server: Exchange Server 2007, Exchange Server 2010 * Microsoft SQL Server: SQL Server 2008, SQL Server 2010, SQL Server 2014
Apa yang baru dalam rilis ini:
High Performance Indexing
Keterbatasan :
30-hari percobaan
Komentar tidak ditemukan