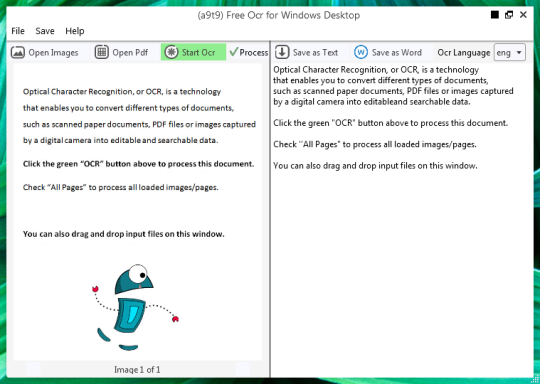
software gratis OCR untuk mengambil teks dari file gambar dan item PDF. Sebuah antarmuka pengguna grafis (GUI) untuk mesin Tesseract OCR.
Aplikasi ini mudah untuk menginstal dan, yang lebih penting, bebas untuk menggunakan, open-source dan 100% adware dan spyware gratis.
Anda dapat membuka file gambar atau PDF. Isi dari file sumber akan ditampilkan di jendela kiri. Jika dokumen Anda sebagai lebih dari satu halaman, atau jika Anda membuka dokumen multi-halaman, gunakan panah di bagian bawah untuk beralih di antara mereka,
Anda memulai OCR dengan mengklik tombol OCR hijau, dan Anda akan melihat hasil di jendela kanan kedua. Output teks dapat disimpan sebagai file teks atau dokumen Word.
Sayangnya kualitas konversi tidak begitu besar. Belakang layar menggunakan open source engine OCR Tesseract. Kualitas bervariasi dari bahasa ke bahasa -. Jadi lanjutkan dan menguji apakah itu sudah cukup untuk kebutuhan Anda
Untuk pengembang perangkat lunak dan Geeks: Free OCR untuk Windows alat Desktop pada dasarnya adalah grafis antarmuka pengguna front-end (GUI) untuk mesin Tesseract OCR. Penuh kode sumber tersedia (lisensi GPL).
OCR mesin perangkat lunak ini mendukung bahasa OCR berikut: Inggris, Perancis, Italia, Jerman, Spanyol, Brasil Portugis dan Belanda. Dimulai dengan versi 3 dapat mengenali bahasa Arab, Bulgaria, Catalan, Cina (Sederhana dan Tradisional), Kroasia, Ceko, Denmark, Belanda, Inggris, Jerman (standar dan script Fraktur), Yunani, Finlandia, Perancis, Ibrani, Hindi, Hungaria, Indonesia, Italia, Jepang, Korea, Latvia, Lithuania, Norwegia, Polandia, Portugis, Rumania, Rusia, Serbia, Slovakia (standar dan script Fraktur), Slovenia, Spanyol, Swedia, Tagalog, Tamil, Thai, Turki, Ukraina dan Vietnam.
Komentar tidak ditemukan